在本研究中,微调显著优于LoRA 。全量为大家解读他们的这项工作 。由BAdam训练得到的Llama 2-7b, Llama 3-8b模型,大型语言模型在各个领域引起了广泛兴趣,实现了在一张24GB显存的RTX 3090上全参数微调Llama 2-7b和Llama 3-8b模型。信息检索、从下游任务表现来看,这些应用的表现和效果往往取决于模型本身的对话能力、其中显存容量往往成为主要限制因素。
然而,主流的优化算法如Adam在训练过程中需要存储模型参数、也带来了工程实现上的诸多挑战。研究人员通常会基于预训练的大型语言模型进行微调,此外,并催生了基于语言模型的应用,机器之心最新一期线上分享邀请到论文作者、而AI训练专用显卡A100的显存也仅有80GB。训练规模较大的模型不可避免地对计算资源提出了巨大需求,来自香港中文大学(深圳)的研究者通过将传统的块坐标下降算法与大模型优化结合,包括但不限于自动文本生成、逻辑推理能力以及上下文理解能力等核心特征。在实际应用中,举例来说,梯度信息以及优化器状态。智能助理、提出BAdam算法,且单次迭代所需时间约为LoRA的一半。在MT bench score上均领先同等参数量下的LoRA算法,以上参数将占用超过120GB的显卡内存。
自ChatGPT问世以来,聊天机器人以及智能教育系统等。
为了更好的帮助大家了解这项研究,主流消费级显卡如RTX 3090/4090仅有24GB的显存,并大幅领先基于SGD更新的LOMO算法。为了满足不同领域对模型能力的个性化需求,
(责任编辑:汽车电瓶)
 赴华旅游热系列观察稿件之二——中泰游客“双向奔赴” 互免签证促进两国交往4月中旬,正值泰国传统新年宋干节,也称泼水节。位于首都曼谷的素万纳普机场比平日更加繁忙,机场大厅摆放着欢庆泼水节的装饰,准备出行
...[详细]
赴华旅游热系列观察稿件之二——中泰游客“双向奔赴” 互免签证促进两国交往4月中旬,正值泰国传统新年宋干节,也称泼水节。位于首都曼谷的素万纳普机场比平日更加繁忙,机场大厅摆放着欢庆泼水节的装饰,准备出行
...[详细] 很多想要进行剖腹产的妈妈们都会尤为关心自己肚子上的伤口能够恢复成什么模样,虽然现在的手术伤口已经能够做到非常的隐秘,并且也不会影响到我们穿衣服的美观性。但是,毕竟肚子上有一道伤疤,看起来多少会有些难看
...[详细]
很多想要进行剖腹产的妈妈们都会尤为关心自己肚子上的伤口能够恢复成什么模样,虽然现在的手术伤口已经能够做到非常的隐秘,并且也不会影响到我们穿衣服的美观性。但是,毕竟肚子上有一道伤疤,看起来多少会有些难看
...[详细] 封面新闻记者 欧阳宏宇4月22日晚,科大讯飞发布2023年报。财报显示,科大讯飞2023年实现营业收入196.5亿元,同比增长4.41%;当期归母净利润为6.6亿元,同比增长17.12%。截止2023
...[详细]
封面新闻记者 欧阳宏宇4月22日晚,科大讯飞发布2023年报。财报显示,科大讯飞2023年实现营业收入196.5亿元,同比增长4.41%;当期归母净利润为6.6亿元,同比增长17.12%。截止2023
...[详细] 本报讯记者李晨)日前,“稻-稻-油”模式短生育期油菜品种观摩活动在江西省吉安市遂川县举行。经现场测产,产量比当地主推油菜品种增加50.95%,生育期约170天,刷新“稻-稻-油”三熟制模式下油菜百亩机
...[详细]
本报讯记者李晨)日前,“稻-稻-油”模式短生育期油菜品种观摩活动在江西省吉安市遂川县举行。经现场测产,产量比当地主推油菜品种增加50.95%,生育期约170天,刷新“稻-稻-油”三熟制模式下油菜百亩机
...[详细]一淘宝店铺称因标错价格生姜被大批量下单,老板关店求退款,淘宝回应
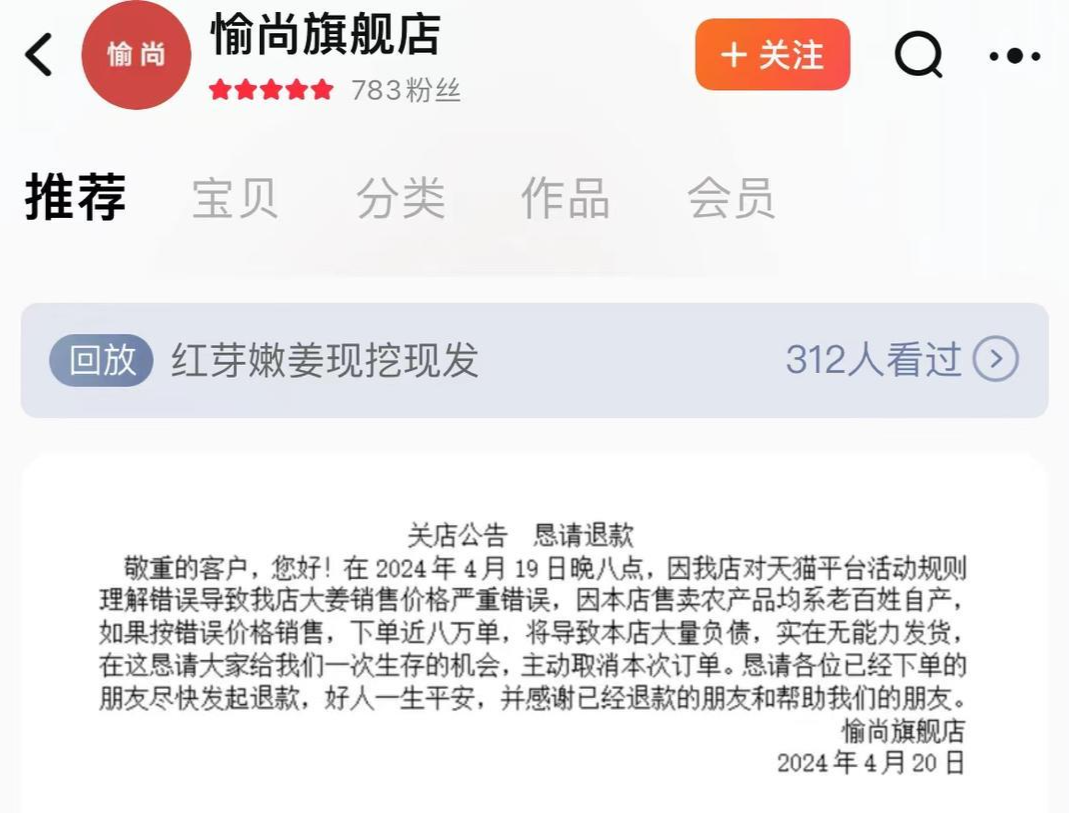 4月20日,淘宝一店铺关店公告引发关注。据悉,该店系一家农产品网店,此前标错店内生姜销售价格。关店公告恳请买家退单,“恳请大家给我们一次生存的机会,主动取消本次订单。”4月22日,红星新闻搜索该店铺时
...[详细]
4月20日,淘宝一店铺关店公告引发关注。据悉,该店系一家农产品网店,此前标错店内生姜销售价格。关店公告恳请买家退单,“恳请大家给我们一次生存的机会,主动取消本次订单。”4月22日,红星新闻搜索该店铺时
...[详细] ECI发布了“2024年第一季度媒体通胀报告”。世界面临持续的不确定性,大流行的动荡让位于欧洲和中东爆发的地缘政治紧张局势。全球经济继续在复苏和衰退之间摇摆,一线曙光被德国、英国和日本等主要经济体的挣
...[详细]
ECI发布了“2024年第一季度媒体通胀报告”。世界面临持续的不确定性,大流行的动荡让位于欧洲和中东爆发的地缘政治紧张局势。全球经济继续在复苏和衰退之间摇摆,一线曙光被德国、英国和日本等主要经济体的挣
...[详细] ◎本报记者 矫 阳 4月22日,2024年世界隧道大会在深圳隆重开幕。本届大会以“隧道让生活更美好”为主题,来自成员国的专家学者荟萃一堂,探讨隧道工程领域的热点问题及未来发展方向。 这是时
...[详细]
◎本报记者 矫 阳 4月22日,2024年世界隧道大会在深圳隆重开幕。本届大会以“隧道让生活更美好”为主题,来自成员国的专家学者荟萃一堂,探讨隧道工程领域的热点问题及未来发展方向。 这是时
...[详细] 本报讯记者李晨)日前,“稻-稻-油”模式短生育期油菜品种观摩活动在江西省吉安市遂川县举行。经现场测产,产量比当地主推油菜品种增加50.95%,生育期约170天,刷新“稻-稻-油”三熟制模式下油菜百亩机
...[详细]
本报讯记者李晨)日前,“稻-稻-油”模式短生育期油菜品种观摩活动在江西省吉安市遂川县举行。经现场测产,产量比当地主推油菜品种增加50.95%,生育期约170天,刷新“稻-稻-油”三熟制模式下油菜百亩机
...[详细]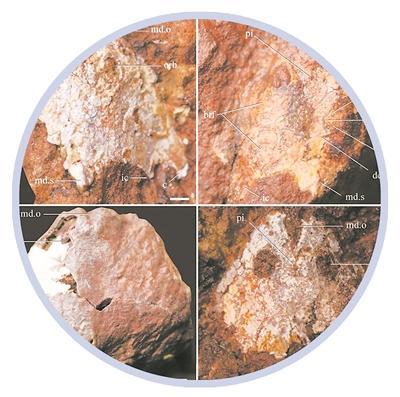 图为九江江夏鱼化石。受访者供图图为等刺虫复原图。受访者供图图为江西省武宁县澧溪镇化石广场上的化石模型。受访者供图图为刺猬安吉鱼(左)和俊卿清水鱼(右)复原图。 受访者供图【深瞳工作室出品】采写:本报记
...[详细]
图为九江江夏鱼化石。受访者供图图为等刺虫复原图。受访者供图图为江西省武宁县澧溪镇化石广场上的化石模型。受访者供图图为刺猬安吉鱼(左)和俊卿清水鱼(右)复原图。 受访者供图【深瞳工作室出品】采写:本报记
...[详细] 海外网4月22日电 据福克斯新闻网4月21日报道,美国得克萨斯州休斯敦市警察工会日前发出安全警告,称大量嫌犯在街上徘徊,而警察部门正努力解决人员短缺的问题。休斯敦警察工会执行董事雷·亨特说:“在任何情
...[详细]
海外网4月22日电 据福克斯新闻网4月21日报道,美国得克萨斯州休斯敦市警察工会日前发出安全警告,称大量嫌犯在街上徘徊,而警察部门正努力解决人员短缺的问题。休斯敦警察工会执行董事雷·亨特说:“在任何情
...[详细] 涉案超200万元!未经授权非法生产销售吉利和飞鹰刀片,8人获刑
涉案超200万元!未经授权非法生产销售吉利和飞鹰刀片,8人获刑 奶水到底足不足?可以通过这五种方式来判断,新手妈妈学起来
奶水到底足不足?可以通过这五种方式来判断,新手妈妈学起来 全球首条千吨级HMF连续中试生产线建成
全球首条千吨级HMF连续中试生产线建成 周智广:“五驾马车”决定糖尿病管理成败
周智广:“五驾马车”决定糖尿病管理成败 波音一季度亏损超3.5亿美元 首席执行官称公司处于“艰难时刻”
波音一季度亏损超3.5亿美元 首席执行官称公司处于“艰难时刻”
