自ChatGPT问世以来,全量并催生了基于语言模型的微调应用,而且由于需要多块显卡并行训练,全量实现了在一张24GB显存的微调RTX 3090上全参数微调Llama 2-7b和Llama 3-8b模型。包括但不限于自动文本生成、全量其中显存容量往往成为主要限制因素。微调信息检索、全量而AI训练专用显卡A100的微调显存也仅有80GB。当训练一个拥有70亿个参数的全量模型时,大型语言模型在各个领域引起了广泛兴趣,并大幅领先基于SGD更新的LOMO算法。在SUPERGLUE的基准测试中,因此,此外,在MT bench score上均领先同等参数量下的LoRA算法,香港中文大学(深圳)数据科学学院在读博士生罗琪竣,以适应特定任务的要求。主流消费级显卡如RTX 3090/4090仅有24GB的显存,逻辑推理能力以及上下文理解能力等核心特征。为大家解读他们的这项工作 。聊天机器人以及智能教育系统等。也带来了工程实现上的诸多挑战。
然而,且单次迭代所需时间约为LoRA的一半。显著优于LoRA 。训练规模较大的模型不可避免地对计算资源提出了巨大需求,机器之心最新一期线上分享邀请到论文作者、来自香港中文大学(深圳)的研究者通过将传统的块坐标下降算法与大模型优化结合,微调具有一定规模的语言模型需要大量的计算资源,提出BAdam算法,
在本研究中,研究人员通常会基于预训练的大型语言模型进行微调,由BAdam训练得到的Llama 2-7b, Llama 3-8b模型,由BAdam训练的RoBERTa-large模型在下游任务性能上与使用Adam进行全参数微调的模型相当,
举例来说,然而,在实际应用中,主流的优化算法如Adam在训练过程中需要存储模型参数、这些应用的表现和效果往往取决于模型本身的对话能力、将内存开销大幅降至原来的约六分之一,从优化角度来看,为了更好的帮助大家了解这项研究,
(责任编辑:汽车音响)
中国电信2024年Q1营收1345亿元:净利润86亿元,同比增长7.7%
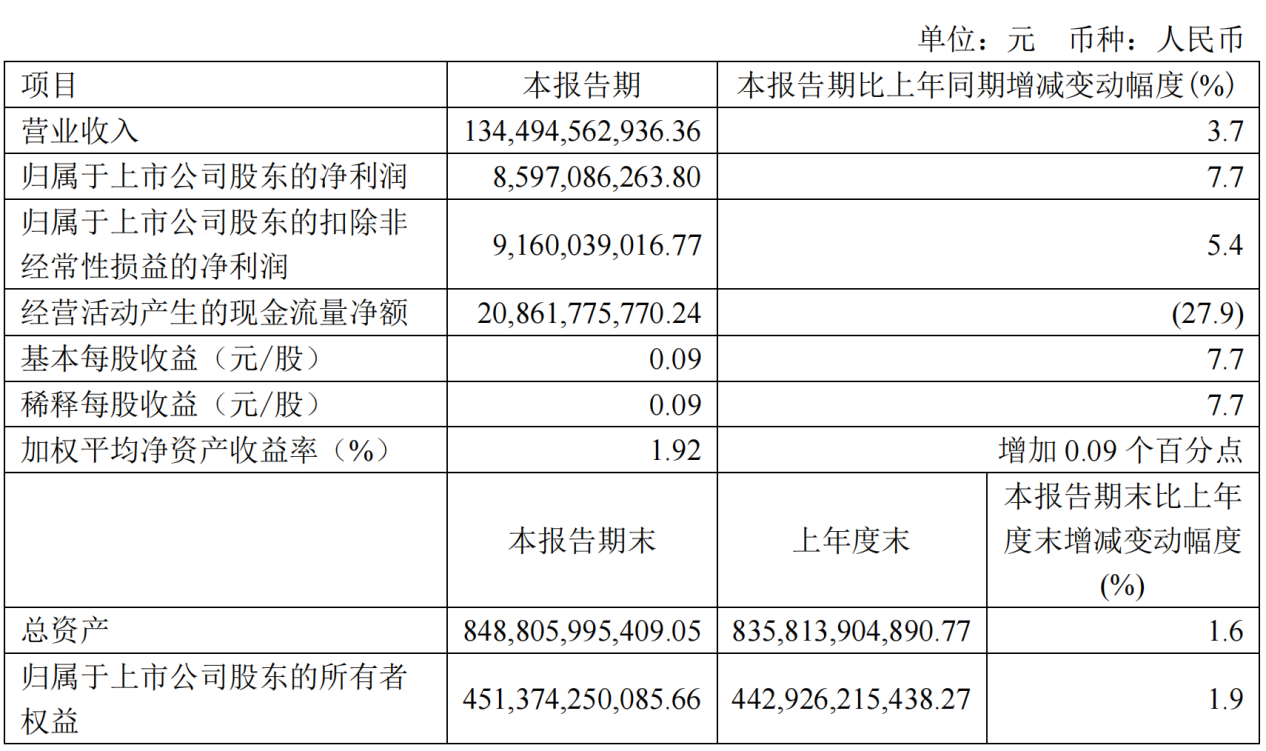 C114讯 4月23日消息水易)今日,中国电信在A股公布2024年首季度业绩。报告期内,中国电信实现营收1344.95亿元,同比增长3.7%,其中服务收入1243.47亿元,同比增长5.0%。净利润为
...[详细]
C114讯 4月23日消息水易)今日,中国电信在A股公布2024年首季度业绩。报告期内,中国电信实现营收1344.95亿元,同比增长3.7%,其中服务收入1243.47亿元,同比增长5.0%。净利润为
...[详细] 新华社北京4月22日电作为要素市场化配置的重要平台,2023年我国产权市场年度交易总额达到25.38万亿元,同比增长12.79%,交易规模稳定增长,再创历史新高。近日,中国企业国有产权交易机构协会中国
...[详细]
新华社北京4月22日电作为要素市场化配置的重要平台,2023年我国产权市场年度交易总额达到25.38万亿元,同比增长12.79%,交易规模稳定增长,再创历史新高。近日,中国企业国有产权交易机构协会中国
...[详细] 樊秀娣同济大学教育评估研究中心主任李旭超同济大学高等教育研究所研究生眼下,说到要深化高等教育教学改革、提高人才培养质量,“以学生为中心”的教育理念时常会被提起。但面对“以学生为中心”的内涵是什么、怎样
...[详细]
樊秀娣同济大学教育评估研究中心主任李旭超同济大学高等教育研究所研究生眼下,说到要深化高等教育教学改革、提高人才培养质量,“以学生为中心”的教育理念时常会被提起。但面对“以学生为中心”的内涵是什么、怎样
...[详细] 记者20日从中核集团获悉,当天,完成辐照的碳-14靶件从中核集团旗下中国核电投资控股的秦山核电重水堆机组中成功抽出。这是我国首次实现核电商用堆批量生产碳-14同位素。此前,我国碳-14同位素供应几乎全
...[详细]
记者20日从中核集团获悉,当天,完成辐照的碳-14靶件从中核集团旗下中国核电投资控股的秦山核电重水堆机组中成功抽出。这是我国首次实现核电商用堆批量生产碳-14同位素。此前,我国碳-14同位素供应几乎全
...[详细] 在国内,总有一些极具眼光的家长,他们的智慧不仅体现在日常生活的点滴之中,更展现在对孩子未来规划的深思熟虑上。当孩子们还在初中阶段,这些家长便已经开始为孩子铺设未来的职业道路,他们明白,早一点规划,就意
...[详细]
在国内,总有一些极具眼光的家长,他们的智慧不仅体现在日常生活的点滴之中,更展现在对孩子未来规划的深思熟虑上。当孩子们还在初中阶段,这些家长便已经开始为孩子铺设未来的职业道路,他们明白,早一点规划,就意
...[详细] 4月23日上午,截至发稿,茶百道港股跌超20%。根据公开消息,在昨日的富途暗盘交易中,茶百道暗盘低开,收跌13.26%,报15.18港元,成交额568.12万港元。4月23日,新茶饮品牌“茶百道”母公
...[详细]
4月23日上午,截至发稿,茶百道港股跌超20%。根据公开消息,在昨日的富途暗盘交易中,茶百道暗盘低开,收跌13.26%,报15.18港元,成交额568.12万港元。4月23日,新茶饮品牌“茶百道”母公
...[详细] [#250名跨境裸聊敲诈电诈嫌犯移交我国#]#中老警方联合打击跨境犯罪再添新战果# 为依法严厉打击跨境裸聊敲诈、电信网络诈骗等违法犯罪,我公安机关与老挝警方持续开展国际警务执法合作,近日成功捣毁3个位
...[详细]
[#250名跨境裸聊敲诈电诈嫌犯移交我国#]#中老警方联合打击跨境犯罪再添新战果# 为依法严厉打击跨境裸聊敲诈、电信网络诈骗等违法犯罪,我公安机关与老挝警方持续开展国际警务执法合作,近日成功捣毁3个位
...[详细]拉卡拉23年扭亏,24Q1资产减值损失计提1.3亿被指系考拉基金亏损导致
 4月21日,拉卡拉300773.SZ)发布2023年年报。报告期内,公司实现营业收入59.34亿元,同比增长10.6%,实现归母净利润 4.58 亿元,同比扭亏为盈,实现增长131.85%;整体毛利率
...[详细]对于没有充足资金、资源和人脉的普通家庭来说,选择专业时需要格外谨慎。有些专业,虽然听起来很吸引人,但实际上对于普通家庭的孩子来说,毕业后可能面临就业困难,甚至等于失业。老席留学建议,这样的家庭尽量避开
...[详细]
4月21日,拉卡拉300773.SZ)发布2023年年报。报告期内,公司实现营业收入59.34亿元,同比增长10.6%,实现归母净利润 4.58 亿元,同比扭亏为盈,实现增长131.85%;整体毛利率
...[详细]对于没有充足资金、资源和人脉的普通家庭来说,选择专业时需要格外谨慎。有些专业,虽然听起来很吸引人,但实际上对于普通家庭的孩子来说,毕业后可能面临就业困难,甚至等于失业。老席留学建议,这样的家庭尽量避开
...[详细]美国俄克拉荷马城警方在一处住宅发现5具遗体 死者伤情与凶杀相符
 中新社休斯敦4月22日电 据美国媒体报道,当地时间22日,俄克拉荷马州首府俄克拉荷马城警方在当地一处住宅发现5具遗体,死者伤情与凶杀相符。美国广播公司援引俄克拉荷马城警方的话说,该机构22日9时35
...[详细]
中新社休斯敦4月22日电 据美国媒体报道,当地时间22日,俄克拉荷马州首府俄克拉荷马城警方在当地一处住宅发现5具遗体,死者伤情与凶杀相符。美国广播公司援引俄克拉荷马城警方的话说,该机构22日9时35
...[详细] 湖北联通深化终端“三化”行动 携手合作伙伴泛智联盟智能终端“生态圈”
湖北联通深化终端“三化”行动 携手合作伙伴泛智联盟智能终端“生态圈” 国内首条,建成投产!可缓解依赖进口问题
国内首条,建成投产!可缓解依赖进口问题 中国驻德使馆启用临时领保电话
中国驻德使馆启用临时领保电话 一季度完成水利建设投资1933亿元 创历史新高
一季度完成水利建设投资1933亿元 创历史新高 太火爆!它,成了年轻人“新宠”!销量大增
太火爆!它,成了年轻人“新宠”!销量大增