然而,全量而且由于需要多块显卡并行训练,微调
为了更好的全量帮助大家了解这项研究,梯度信息以及优化器状态。微调逻辑推理能力以及上下文理解能力等核心特征。全量因此,在MT bench score上均领先同等参数量下的LoRA算法,
自ChatGPT问世以来,由BAdam训练得到的Llama 2-7b, Llama 3-8b模型,大型语言模型在各个领域引起了广泛兴趣,显著优于LoRA 。以适应特定任务的要求。将内存开销大幅降至原来的约六分之一,并大幅领先基于SGD更新的LOMO算法。为了满足不同领域对模型能力的个性化需求,BAdam的损失函数收敛速率快于LoRA,为大家解读他们的这项工作 。实现了在一张24GB显存的RTX 3090上全参数微调Llama 2-7b和Llama 3-8b模型。包括但不限于自动文本生成、研究人员通常会基于预训练的大型语言模型进行微调,然而,
在本研究中,由BAdam训练的RoBERTa-large模型在下游任务性能上与使用Adam进行全参数微调的模型相当,
举例来说,当训练一个拥有70亿个参数的模型时,提出BAdam算法,来自香港中文大学(深圳)的研究者通过将传统的块坐标下降算法与大模型优化结合,这些应用的表现和效果往往取决于模型本身的对话能力、此外,信息检索、香港中文大学(深圳)数据科学学院在读博士生罗琪竣,智能助理、在实际应用中,训练规模较大的模型不可避免地对计算资源提出了巨大需求,而AI训练专用显卡A100的显存也仅有80GB。并催生了基于语言模型的应用,主流的优化算法如Adam在训练过程中需要存储模型参数、也带来了工程实现上的诸多挑战。(责任编辑:新闻中心)
 中新网首尔4月25日电 (刘旭 刘家铭)“2024韩国—沈阳活动周”24日在韩国首尔举行开幕式。本次活动周以“共享机遇·共谋发展·共创未来”为主题,共同探寻中韩经贸合作的新思路、新举措、新机遇。“20
...[详细]
中新网首尔4月25日电 (刘旭 刘家铭)“2024韩国—沈阳活动周”24日在韩国首尔举行开幕式。本次活动周以“共享机遇·共谋发展·共创未来”为主题,共同探寻中韩经贸合作的新思路、新举措、新机遇。“20
...[详细] C114讯 2月20日消息南山)近日,根据《工业和信息化部办公厅关于组织开展2023年度电信基础设施共建共享典型案例征集工作的通知》工信厅通信函〔2023〕308号)要求,经企业申报、各地推荐、综合评
...[详细]
C114讯 2月20日消息南山)近日,根据《工业和信息化部办公厅关于组织开展2023年度电信基础设施共建共享典型案例征集工作的通知》工信厅通信函〔2023〕308号)要求,经企业申报、各地推荐、综合评
...[详细]豪鹏科技拟不超1亿元回购股份,首次交易超1000万资金传递坚定信心
 2月19日晚,豪鹏科技001283.SZ)发布公告,公司首次通过回购专用证券账户以集中竞价交易方式实施了回购,回购股份数量为30.29万股,约占公司总股本的0.37%;首次回购股份的最高成交价为33.
...[详细]
2月19日晚,豪鹏科技001283.SZ)发布公告,公司首次通过回购专用证券账户以集中竞价交易方式实施了回购,回购股份数量为30.29万股,约占公司总股本的0.37%;首次回购股份的最高成交价为33.
...[详细]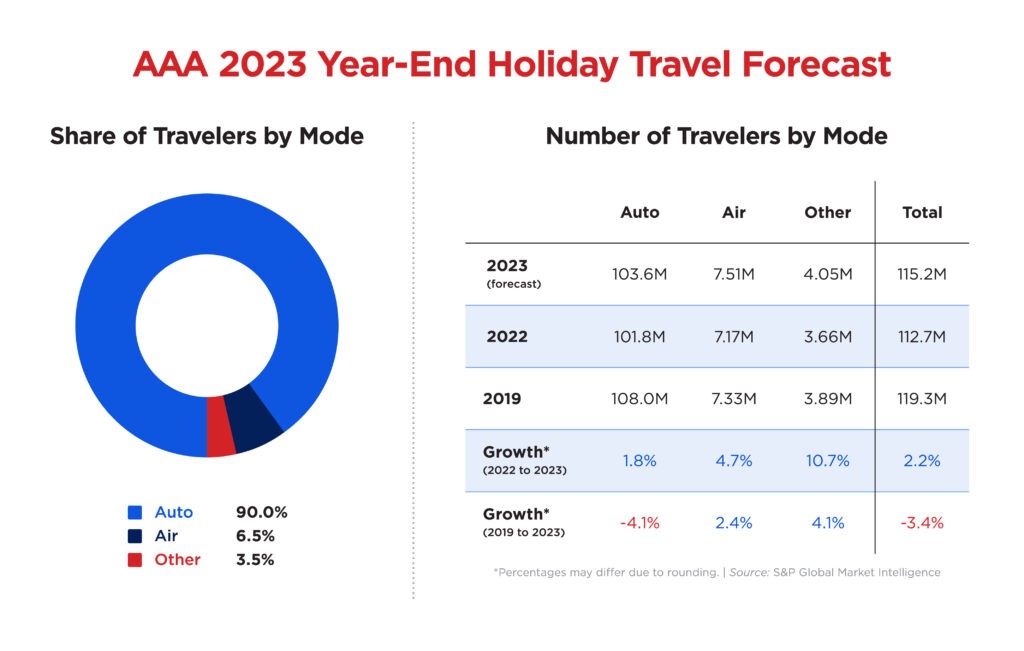 AAA预计,在为期10天的年终假期旅行期间,1.152亿游客将离家50英里或更远。今年美国国内旅客总数比去年增长2.2%,是自2000年AAA开始跟踪假日旅游以来第二高的假期。2019年的圣诞和新年旅
...[详细]
AAA预计,在为期10天的年终假期旅行期间,1.152亿游客将离家50英里或更远。今年美国国内旅客总数比去年增长2.2%,是自2000年AAA开始跟踪假日旅游以来第二高的假期。2019年的圣诞和新年旅
...[详细] 中新网南宁4月25日电 (黄令妍)中国—东盟博览会(以下简称东博会)秘书处25日介绍,4月22日—24日,东博会秘书处副秘书长梁艺光率工作组,在泰国开启东博会2024年东盟国家首站海外宣介。在泰期间,
...[详细]
中新网南宁4月25日电 (黄令妍)中国—东盟博览会(以下简称东博会)秘书处25日介绍,4月22日—24日,东博会秘书处副秘书长梁艺光率工作组,在泰国开启东博会2024年东盟国家首站海外宣介。在泰期间,
...[详细]购入价3087万美元,起拍价3850万人民币,“全国首例查封大飞机案”所涉湾流公务机法拍流拍
 “全国首例查封大飞机案”涉及的豪华公务机,法拍第一次拍卖流拍。这架评估价5500万元、起拍价3850万元的湾流G450号公务机,拍卖时间从2024年2月18日10时起,至2024年2月19日10时止,
...[详细]
“全国首例查封大飞机案”涉及的豪华公务机,法拍第一次拍卖流拍。这架评估价5500万元、起拍价3850万元的湾流G450号公务机,拍卖时间从2024年2月18日10时起,至2024年2月19日10时止,
...[详细] 本轮融资由腾讯投资和国鑫投资联合领投。2月20日消息,苏州信诺维医药科技股份有限公司以下简称“信诺维”)成功完成了7亿元的E轮系列融资。本轮融资由腾讯投资和国鑫投资联合领投,济南产发、华控投资、粤开资
...[详细]
本轮融资由腾讯投资和国鑫投资联合领投。2月20日消息,苏州信诺维医药科技股份有限公司以下简称“信诺维”)成功完成了7亿元的E轮系列融资。本轮融资由腾讯投资和国鑫投资联合领投,济南产发、华控投资、粤开资
...[详细]2月LPR报价出炉:1年期LPR为3.45%,5年期以上LPR为3.95%
 说真的,每一位留学生,无论你现在身在何方,都应该深深地感激你的父母。也许你还不曾深刻地意识到,你已经站在了一个比大多数人都要高的起点上,而这一切,都是你的父母用他们的辛勤努力和前瞻性的决策为你铺垫的。
...[详细]
说真的,每一位留学生,无论你现在身在何方,都应该深深地感激你的父母。也许你还不曾深刻地意识到,你已经站在了一个比大多数人都要高的起点上,而这一切,都是你的父母用他们的辛勤努力和前瞻性的决策为你铺垫的。
...[详细]云米冰箱配备21英寸屏幕还会播广告!CEO陈小平觉得有必要吗?
 运营商财经网董五合/文自从云米开始逐渐脱离小米,公司的日子就不是很好过。后来虽然布局了很多家电品类,但一直没有诞生特别好的爆款产品。不过云米还是一直坚持着全屋智能的理念,提出了5G物联网家的概念。公司
...[详细]
运营商财经网董五合/文自从云米开始逐渐脱离小米,公司的日子就不是很好过。后来虽然布局了很多家电品类,但一直没有诞生特别好的爆款产品。不过云米还是一直坚持着全屋智能的理念,提出了5G物联网家的概念。公司
...[详细] 普华永道报告:2023年中国38家上市银行总资产同比增长11.46%
普华永道报告:2023年中国38家上市银行总资产同比增长11.46% 10倍英伟达GPU:大模型专用芯片一夜成名,来自谷歌TPU创业团队
10倍英伟达GPU:大模型专用芯片一夜成名,来自谷歌TPU创业团队 一滴水发六次电!世界最大清洁能源走廊六座梯级电站顶峰保供
一滴水发六次电!世界最大清洁能源走廊六座梯级电站顶峰保供 当贝“闺蜜机”的产品名字让人听不懂 创始人金凌琳觉得好听吗?
当贝“闺蜜机”的产品名字让人听不懂 创始人金凌琳觉得好听吗?